9/16/2025
VibeVoice TTS — Multi-Speaker, Long-Form Text-to-Speech for Natural Conversations
VibeVoice - Advanced Multi-Speaker Text-to-Speech AI
What is VibeVoice - Microsoft's Multi-Speaker TTS Model
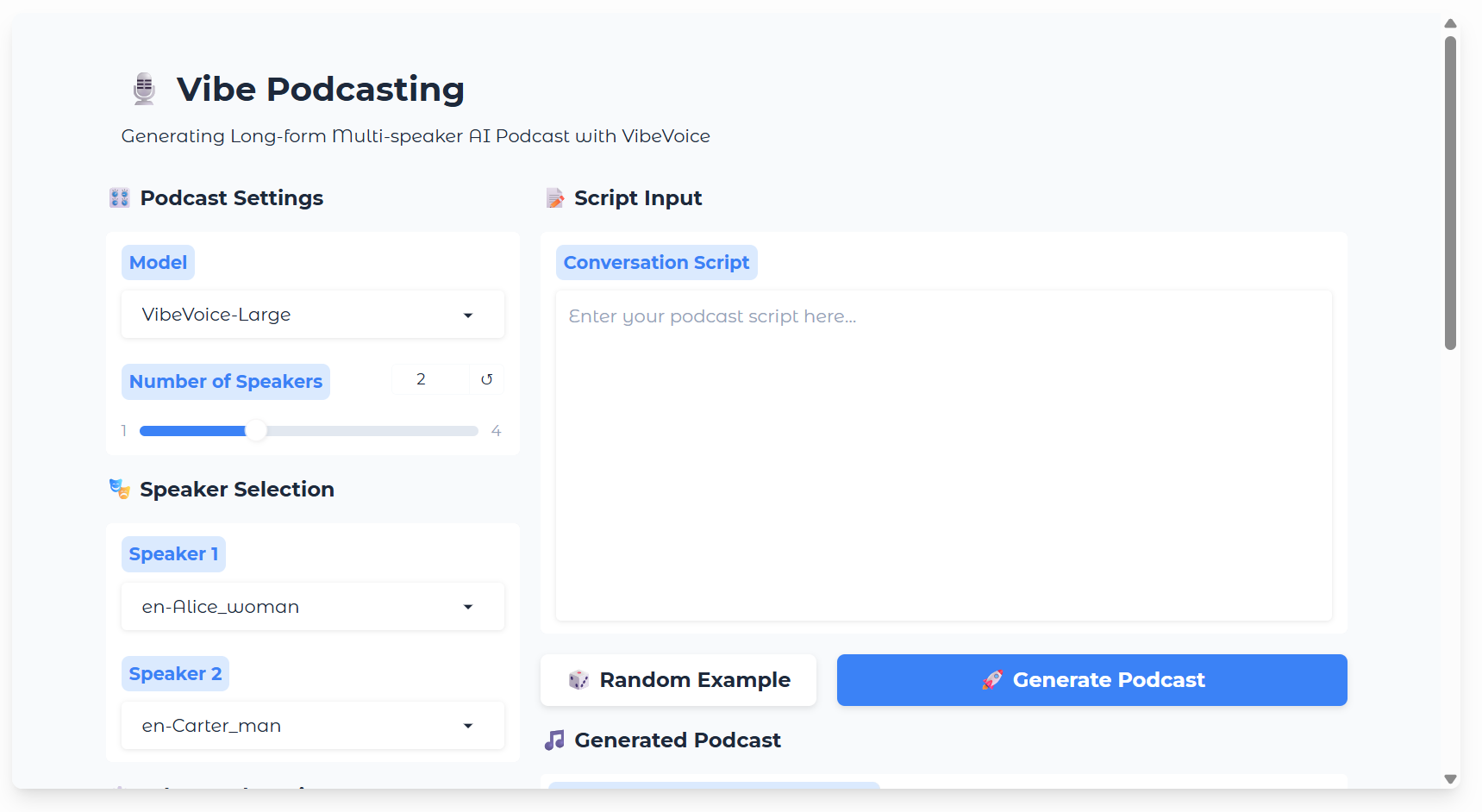
VibeVoice is Microsoft's open-source text-to-speech (TTS) model purpose-built for multi-speaker, long-form, conversation-style audio. It can generate up to ~90 minutes of natural, turn-taking dialogue with up to four speakers, making it ideal for podcasts, audiobooks, and e-learning narration.
Powered by continuous speech tokenizers (~7.5 Hz) and a next-token diffusion decoder, VibeVoice maintains strong speaker consistency and natural prosody over long sequences. For creators, it works as a podcast voice generator, supports long text-to-speech narration, and enables multi-speaker dialogue synthesis.
The project is MIT-licensed, so you can run it locally or try it via hosted demos.
VibeVoice Demos - AI Text-to-Speech in Action
Watch How VibeVoice Generates Natural Multi-Speaker Conversations
VibeVoice FAQ - Common Questions About Multi-Speaker TTS
How long and how many speakers per generation?
Up to ~90 minutes and up to 4 speakers in one pass, depending on the chosen variant, compute, and hosting limits.
Which languages are supported?
Primarily English and Chinese. Cross-lingual and singing abilities are emergent and may be unstable depending on script and prompts.
What are the typical use cases?
Podcast voice generator, interview/panel dialogues, audiobook conversations, long text-to-speech course narration, role-play, and customer-service simulations.
How is it different from traditional single-speaker TTS?
VibeVoice focuses on conversation TTS: multi-speaker, natural turn-taking, and long-duration stability. Traditional TTS often targets single-speaker short text and is weaker for dialogues and very long content.
How should I structure my script?
Label each line with a speaker (e.g., "Alice: …"), keep sentences short, follow natural turns, and prefer simple punctuation. Add pauses or stage directions only when necessary.
How do I reduce artifacts like background music or odd prosody?
Try a different voice/prompt, split long sentences, soften emotional cues, or post-process with light denoise. For very long projects, generate per chapter and stitch.
Does it support voice cloning or celebrity mimicry?
The public demos generally do not offer voice cloning. Do not mimic real people without consent; follow applicable laws and platform rules.
What export formats are available? Who owns the output?
You can download audio (commonly WAV/MP3, depending on the demo). You're responsible for ensuring copyright/compliance when using or publishing the output.
VibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text. It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking. A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz. These tokenizers efficiently preserve audio fidelity while significantly boosting computational efficiency for processing long sequences. VibeVoice employs a next-token diffusion framework, leveraging a Large Language Model (LLM) to understand textual context and dialogue flow, and a diffusion head to generate high-fidelity acoustic details. The model can synthesize speech up to 90 minutes long with up to 4 distinct speakers, surpassing the typical 1-2 speaker limits of many prior models.